

NVIDIA AI Releases Nemotron-Labs-Diffusion: A Tri-Mode Language Model with 6× Tokens Per Forward Over Qwen3-8B

NVIDIA researchers have released Nemotron-Labs-Diffusion, a language model family that unifies three decoding modes in one architecture. The model supports autoregressive (AR) decoding, diffusion-based parallel decoding, and self-speculation decoding. It is available in 3B, 8B, and 14B parameter sizes. The family includes base, instruct, and vision-language variants.
Sequential Decoding Limits Throughput
Standard autoregressive (AR) language models generate text one token at a time, left to right. Each token depends on all previous tokens. This sequential dependency limits GPU parallelism per generation step. The result is low hardware utilization at low batch sizes — the typical setting for single-user or edge deployment.
Diffusion language models (LMs) offer a different approach. Instead of generating tokens sequentially, they denoise multiple tokens in parallel per forward pass. This enables higher throughput. The tradeoff has been accuracy: diffusion LMs have consistently lagged behind AR models on benchmarks, requiring substantially more data to reach comparable performance. A key reason is that diffusion training treats all token permutations uniformly, rather than leveraging the strong left-to-right prior inherent in natural language.
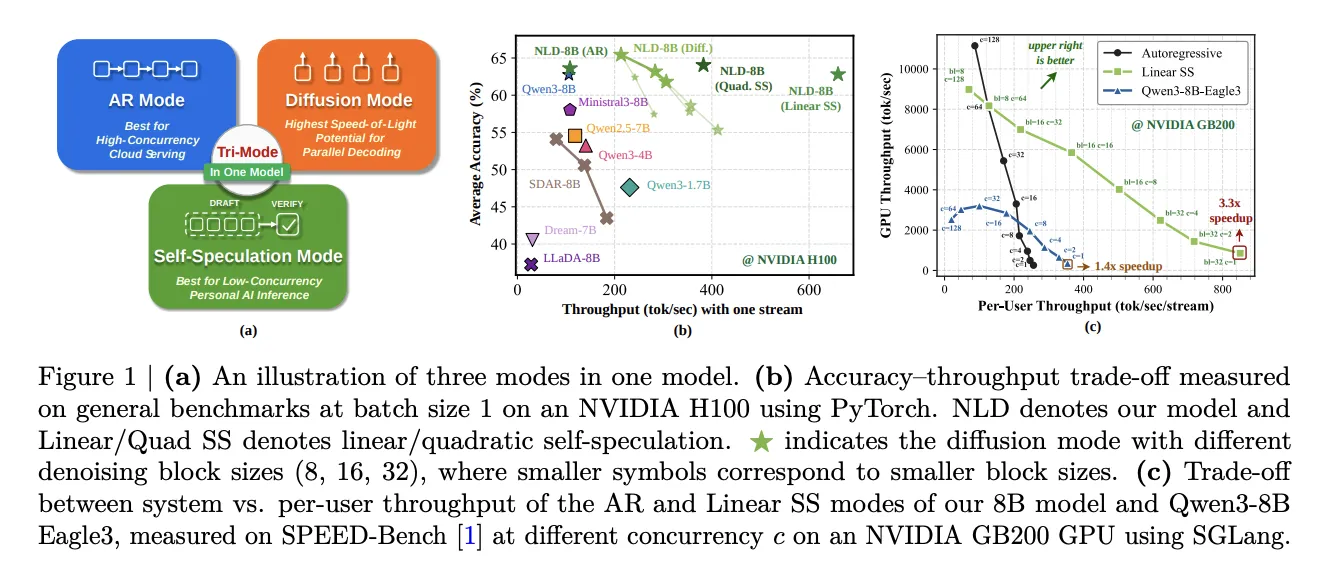
What Is a Tri-Mode Language Model?
Nemotron-Labs-Diffusion is trained on a joint AR-diffusion objective. At inference time, it operates in three modes depending on the deployment context. There are no mode-specific architectural modifications — the same weights serve all three modes.
AR mode is standard left-to-right autoregressive decoding using causal attention. This mode is best suited for high-concurrency cloud serving.
Diffusion mode denoises multiple tokens in parallel within a fixed-length block. The sequence is partitioned into contiguous blocks. Within each block, tokens attend bidirectionally. Across blocks, attention remains causal, so prior blocks can reuse their KV cache. A lightweight trained sampler predicts, per masked position, whether the model’s top-1 prediction at the current denoising step is correct. Positions predicted as correct are committed in that step. This allows the model to commit multiple tokens per forward pass.
Self-speculation mode uses the diffusion pathway to draft candidate tokens and the AR pathway to verify them, within the same single model. No auxiliary draft model or separate prediction head is required. The diffusion pathway generates a block of k candidate tokens in parallel. The AR pathway then runs a second forward pass over those candidates using causal attention, verifying the longest contiguous prefix that matches AR predictions. Each cycle produces between 1 and k+1 verified tokens. This contrasts with Multi-Token Prediction (MTP) methods such as Eagle3, which use small auxiliary draft heads attached to an AR backbone.
Training
The joint training objective combines an AR next-token prediction loss and a block-wise diffusion denoising loss:
ℒ(θ) = ℒ_AR(θ) + α · ℒ_diff(θ)
The coefficient α is set to 0.3 across all training stages. Ablation experiments varying α from 0.1 to 1.0 show that both AR-mode and diffusion-mode accuracy peak at α = 0.3. No value in the range [0.1, 0.5] improves one mode at the expense of the other — the two objectives rise and fall together.
Two-stage training first trains the model purely on the AR objective for 1 trillion tokens, building strong left-to-right linguistic priors. Stage 2 then introduces the joint objective for 300 billion additional tokens. In ablations, two-stage training contributed +5.74% average accuracy. Adding the AR loss contributed the single largest gain at +7.48%. Global loss averaging — treating all tokens across a batch equally rather than averaging per-sequence first — contributed +2.12% by reducing gradient variance from variable diffusion masking ratios. Cumulatively, the full training pipeline improved the baseline by 16.05% average accuracy.
All models are initialized from pretrained Ministral3 base models, not trained from scratch. Training was performed on 256 NVIDIA H100 GPUs. Instruct models are trained via supervised fine-tuning (SFT) on 45 billion tokens on top of the base models, using the same joint AR-diffusion objective with α = 0.3. The training and inference pipeline is released through Megatron Bridge.
LoRA-Enhanced Linear Self-Speculation
The base diffusion-to-AR alignment in self-speculation can be improved with a LoRA adapter. This adapter is fine-tuned on the diffusion draft pathway to better align its output with the AR verifier. It targets only the o_proj layer of the attention module (rank 128, α = 512, approximately 36M trainable parameters, 0.4% of the backbone). LoRA tuning improves tokens per forward (TPF) by 14.4%, 32.5%, and 27.6% at the 3B, 8B, and 14B scales respectively, with negligible accuracy change.
Speed-of-Light Analysis
The research team reports a speed-of-light (SOL) analysis — a theoretical upper bound on tokens per forward pass achievable by the diffusion mode, assuming an oracle sampler that correctly identifies all positions that can be safely committed in parallel.
At block length 32, the SOL acceptance rate reaches 7.60× on average, exceeding 10× on coding and multilingual tasks. Current confidence-based sampling achieves approximately 3× TPF at comparable accuracy, leaving a large gap to the SOL ceiling.
Comparing against linear self-speculation: both approach similar acceptance rates (6.82× for linear self-speculation vs. 7.60× SOL). However, the real tokens per forward pass (TPF) gap is much larger — 6.02× for SOL versus 3.41× for linear self-speculation, a 76.5% difference. Linear self-speculation requires two forward passes per cycle (one diffusion draft, one AR verify) and accepts only a contiguous prefix. These two constraints cap its real TPF well below SOL, even when drafter and verifier are well aligned.
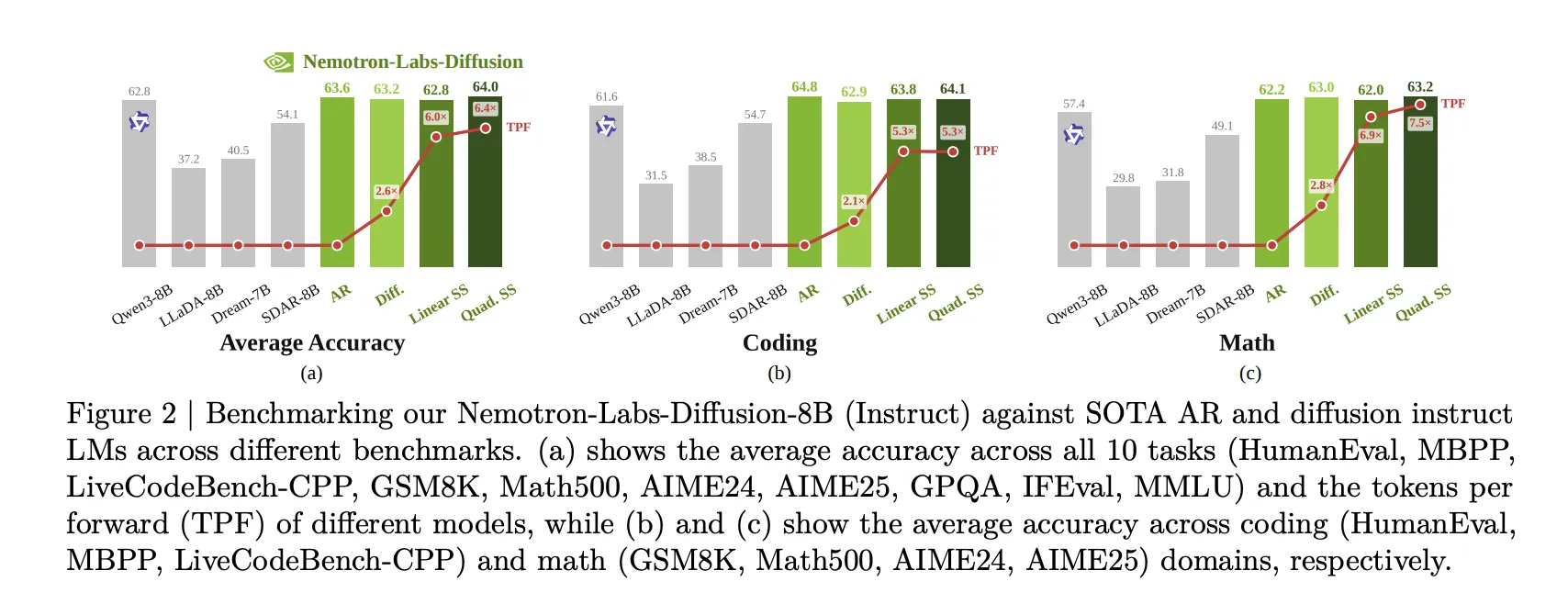
Benchmark Results
On the 10-task instruct evaluation (HumanEval, MBPP, LiveCodeBench-CPP, GSM8K, Math500, AIME24, AIME25, GPQA, IFEval, MMLU):
NLD-8B AR mode: 63.61% average accuracy, versus 62.75% for Qwen3-8B and 58.02% for Ministral3-8B-Instruct.
NLD-8B diffusion mode: 63.18% average accuracy with 2.57× TPF.
NLD-8B LoRA-tuned linear self-speculation: 62.81% average accuracy with 5.99× TPF.
NLD-8B quadratic self-speculation: 64.04% average accuracy with 6.38× TPF.
On SPEED-Bench with SGLang on an NVIDIA GB200 GPU, linear self-speculation achieves 4× higher throughput than Qwen3-8B and 3.3× speedup over the NLD-8B AR mode at concurrency 1 (3.97× with an optimized CUDA kernel). Compared to Qwen3-8B-Eagle3, linear self-speculation delivers a 2.4×, 2.3×, and 1.8× speedup at batch size 1 on GB200, RTX Pro 6000, and DGX Spark respectively.
Acceptance length is the underlying reason for this advantage. Across SPEED-Bench categories, NLD achieves average acceptance lengths of 5.46 (native) and 6.82 (with LoRA) tokens per draft step. Eagle3 averages 2.75 and Qwen3-9B-MTP averages 4.24. On the four diffusion-friendly categories — coding, math, reasoning, and multilingual — the gap widens further: 8.69 for NLD-LoRA versus 2.81 for Eagle3.
At 14B scale with LoRA-tuned linear self-speculation, NLD-14B achieves 66.36% average accuracy at 5.96× TPF, outperforming Qwen3-14B at 65.17% accuracy in AR mode.
The vision-language model, Nemotron-Labs-Diffusion-VLM-8B, extends the same framework to multimodal tasks. In linear self-speculation mode, it achieves 3.63× to 7.45× TPF — the higher end for responses over 200 tokens — with a 0.1% average accuracy drop versus AR mode.
Marktechpost’s Visual Explainer
Overview
Three Modes
Install
Basic Usage
Self-Speculation
Production Serving
When to Use
Key Takeaways
Nemotron-Labs-Diffusion unifies AR, diffusion, and self-speculation decoding in one model, with no mode-specific architectural changes.
Joint AR-diffusion training is not a tradeoff — both objectives peak at α=0.3 and improve together.
Self-speculation mode achieves 5.99× TPF on the 8B model, with 2.4× higher throughput than Qwen3-8B-Eagle3 at batch size 1 on GB200.
Higher acceptance length is the key differentiator: NLD-LoRA averages 6.82 tokens per draft step versus 2.75 for Eagle3 and 4.24 for MTP.
Speed-of-light analysis shows the diffusion mode has a theoretical ceiling of 7.60× TPF — current confidence-based sampling realizes only ~3×, leaving significant room for sampler improvements.
Check out the Paper, Model Weights and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us








