Google AI Just Released Nano-Banana 2: The New AI Model Featuring Advanced Subject Consistency and Sub-Second 4K Image Synthesis Performance
In the escalating ‘race of “smaller, faster, cheaper’ AI, Google just dropped a heavy-hitting payload. The tech giant officially unveiled Nano-Banana 2 (technically designated as Gemini 3.1 Flash Image). Google is making a definitive pivot toward the edge: high-fidelity, sub-second image synthesis that stays entirely on your device.
The Technical Leap: Efficiency over Scale
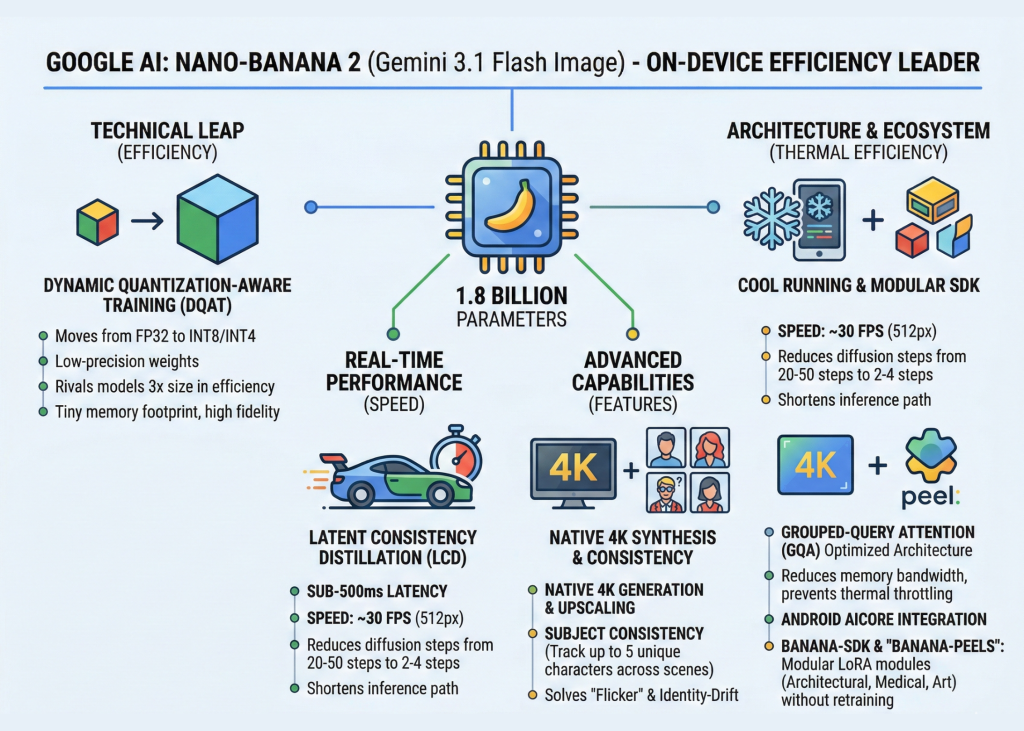
The first version Nano-Banana was a proof-of-concept for mobile reasoning. Version 2, however, is built on a 1.8 billion parameter backbone that rivals models 3x its size in efficiency.
Google AI team achieved this through Dynamic Quantization-Aware Training (DQAT). In software engineering terms, quantization typically involves down-casting model weights from FP32 (32-bit floating point) to INT8 or even INT4 to save memory. While this usually degrades output quality, DQAT allows Nano-Banana 2 to maintain a high signal-to-noise ratio. The result? A model with a tiny memory footprint that doesn’t sacrifice the ‘texture’ of high-end generative AI.
Real-Time Performance: The LCD Breakthrough
TNano-Banana 2 clocks in at sub-500 millisecond latencies on mid-range mobile hardware. In a live demo, the model generated roughly 30 frames per second at 512px, effectively achieving real-time synthesis.
This is made possible by Latent Consistency Distillation (LCD). Traditional diffusion models are computationally expensive because they require 20 to 50 iterative ‘denoising’ steps to produce an image. LCD allows the model to predict the final image in as few as 2 to 4 steps. By shortening the inference path, Google has bypassed the ‘latency friction’ that previously made on-device generative AI feel sluggish.
4K Native Generation and Subject Consistency
Beyond speed, the model introduces two features that solve long-standing pain points for devs:
Native 4K Synthesis: Unlike its predecessors which were capped at 1K or 2K, Nano-Banana 2 supports native 4K generation and upscaling. This is a massive win for mobile UI/UX designers and mobile gaming developers.
Subject Consistency: The model can track and maintain up to five consistent characters across different generated scenes. For engineers building storytelling or content creation apps, this solves the “flicker” and identity-drift issues that plague standard diffusion pipelines.
Architecture: Cool Running with GQA
For the systems engineers, the most impressive feature is how Nano-Banana 2 manages thermals. Mobile devices often throttle performance when GPUs/NPUs overheat. Google mitigated this by implementing Grouped-Query Attention (GQA).
In standard Transformer architectures, the attention mechanism is a memory-bandwidth hog. GQA optimizes this by sharing key and value heads, significantly reducing the data movement required during inference. This ensures the model runs ‘cool,’ preventing the performance dips that usually occur during extended AI-heavy tasks.
The Developer Ecosystem: Banana-SDK and ‘Peels‘
Google is doubling down on the ‘Local-First’ philosophy by integrating Nano-Banana 2 directly into Android AICore. For software devs, this means standardized APIs for on-device execution.
The launch also introduced the Banana-SDK, which facilitates the use of ‘Banana-Peels‘—Google’s branding for specialized LoRA (Low-Rank Adaptation) modules. These allow developers to ‘snap on’ specific fine-tuned weights for niche tasks—such as architectural rendering, medical imaging, or stylized character art—without needing to retrain the base 1.8B parameter model.
Key Takeaways
Sub-Second 4K Generation: Leveraging Latent Consistency Distillation (LCD), the model achieves sub-500ms latency, enabling real-time 4K image synthesis and upscaling directly on mobile hardware.
‘Local-First’ Architecture: Built on a 1.8 billion parameter backbone, the model uses Dynamic Quantization-Aware Training (DQAT) to maintain high-fidelity output with a minimal memory footprint, eliminating the need for expensive cloud inference.
Thermal Efficiency via GQA: By implementing Grouped-Query Attention (GQA), the model reduces memory bandwidth requirements, allowing it to run continuously on mobile NPUs without triggering thermal throttling or performance dips.
Advanced Subject Consistency: A breakthrough for storytelling apps, the model can maintain identity for up to five consistent characters across multiple generated scenes, solving the common ‘identity drift’ issue in diffusion models.
Modular ‘Banana-Peels’ (LoRAs): Through the new Banana-SDK, developers can deploy specialized Low-Rank Adaptation (LoRA) modules to customize the model for niche tasks (like medical imaging or specific art styles) without retraining the base architecture.
Check out the Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.